

Introduction
There are a lot of libraries to scrap data from the web that Python provides to us. For this blog, I will tell you as much as I know about the Scrapy web framework.
But, first of all, we must learn what is the difference between Web Crawling and Web Scraping ?
The difference between Web Crawling & Web Scraping :
- Web Crawling is the process of using
crawl agentsorspidersto read, navigates web pages and store all of the content of these web pages for indexing and pulling content, it means that crawlers extract data or save the keywords, the images and the URLs of web pages and store/index them. This process is used by the majority of Search Engines because it helps it to gives you the information and the page of this information which you’re looking for by crawling all the contents of the web pages and index them on the Search engine.
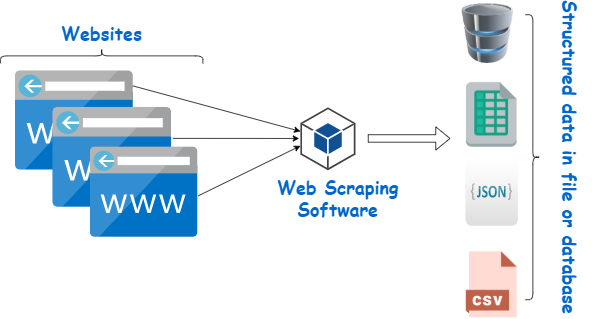
- Web Scraping is the process of extracting structured data and information from a web page, e.g. to collect some specific information like product details, prices, categories… After that, these data can be extracted to
a file or a database.
- There are some similarities bewtween Web Crawling and Web Scraping, but I think the main difference is Web Scraping has much more focused purpose while Web Crawler scan, track and extract all data on a website.
Scrapy
Scrapy is a Web spider or framework for crawling and fetching data from several websites. It can do big jobs very easily and quickly. This web famework crawl a group of URLs in no more than a minute and does it very smoothly as it uses Twister which works asynchronously for concurrency.
If you want to get more about the Twisted API here is the link : Twisted API
There are some other powerful libraries to scrap data from web pages like BeautifulSoup but it’s just for small projects.
I choose to talk about Scrapy because it’s more faster than others, used for large data, and used by the most popular search engine for providing a fast searching. So, Scrapy does many features you could probably need in your web scraping and other advantages.
First, for building a Scrapy project you will have to set up a new startproject and run the following command :
1
scrapy startproject tutorial
However, my project directory will be created with the following structure :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
tutorial/
scrapy.cfg # it's a configuration file
tutorial/ # prject module
__init__.py
items.py # acts like the model
middlewares.py # it's for project middlwares, but I didn't use it
pipelines.py # it's for project pipelines, but I didn't use it
settings.py # project settings file
spiders/ # in this directory you could add a specific spider for scraping
__init__.py
Then, you can start to develop your first spider which is a scraper for scraping data from specific websites wich is my ProductSpider class which extends from scrapy.Spider class from which every spider should inherit, and then define my start_requests and parse for extracting data.
The following code is ProductSpider class :
1
2
3
4
5
6
7
8
9
10
11
12
13
class ProductSpider(scrapy.Spider):
name = "product"
def start_requests(self):
urls = [
# my urls where I want to crawl or scrap from
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
# Here it's up to you to store your data on a file or database or doing some other parts of code
So, to understand what heppened under the hood, the superclass
scrapy.Spiderjust provides a defaultstart_requests()implementation which sends requests from thestart_urlsspider attribute and calls the spider methodparse()for each of the resulting requests. In other way,start_requests()is a generator function which returns a generator of Request objects which are scheduled by Scrapy. Upon receiving a response for each one, your spider instanciates a Response objects and calls the callback method associated with the request and passing the response as an argument.Noticed that after receiving the Response objects, we can use
selectorsbecause they select certain parts of the HTML document specified either by XPath or CSS expressions.
Scrapy Selectors :
XPath is a language for selecting nodes in XML documents, which can also be used with HTML.
CSS is a language for applying styles to HTML documents. It defines selectors to associate those styles with specific HTML elements.
For quering the response objects, we must use XPath or CSS selectors, here are some simple examples for using both of them :
1
2
3
4
5
>>> response.xpath('//div').get()
[<Selector xpath='//div' data='<div>Content to scrap here</div>'>]
>>> response.xpath('//div/text()').get()
'Content to scrap here'
And with CSS selector :
1
2
3
4
5
>>> response.css('div').get()
['<div>Quotes to Scrape</div>']
>>> response.css('div::text').get()
'Content to scrap here'
::textto the CSS query, to mean we want to select only the text elements directly inside <div> element.get()method returns a single result, if there are several matches, content of a first match is returned. ReturnsNoneif there is no matches.However, for the
items.py, it acts like your model for our data, it could be something like that :
1
2
3
4
5
6
7
8
class ProductItem(scrapy.Item):
# Your fields here like
# price = scrapy.Field()
pass
CrawlerRunner and CrawlerProcess classes
After understanding some processes and implementing you spider, in your main code you could use your spider for start crawling using the Crawler API that enables you to run scrapy from a script instead of the command scrapy crawl.
There are two possibilities to to crawl with your spider :
The first one is scrapy.crawler.CrawlerRunner : is a class that encapsulates some simple helpers to run multiple crawlers,if you are using Twisted and want to run your spider in the same reactor, it’s really recommanded to use this class.
The second one is scrapy.crawler.CrawlerProcess : This class extends CrawlerRunner by adding support for starting a reactor, configuring the logging and setting shutdown handlers. This class is the one used by all Scrapy commands.
I am sure you are now asking about what is the Reactor ?
The answer is that Reactor is an the central nervous system of a Twisted application, it is an event loop which waits for events, when an event occurs, it triggers the appropriate event handler function and will perform your actions only in response to events. Because of the crawling request-response process, using an asynchronous event loop is the best way to handle events unlike the traditional sequetial programs. On top of that, it could be used to scheduling, threading and listening for connections from external machines.
Remember that reactor is not restartable, that means if you want to run it more times without finished the execution of the script or interrupt it, it will raise an error because the reactor.run() method cannot restart.
Examples for using CrawlerProcess and CrawlerRunner
A simple example of using the scrapy.crawler.CrawlProcess :
1
2
3
4
5
6
7
8
9
10
import scrapy
from scrapy.crawler import CrawlerProcess
class MySpider(scrapy.Spider):
# Your first spider definition
process = CrawlerProcess()
process.crawl(MySpider)
process.start() # the script will block here until all crawling jobs are finished
A simple example of using the scrapy.crawler.CrawlRunner :
1
2
3
4
5
6
7
8
9
10
11
12
13
from twisted.internet import reactor
from scrapy.crawler import CrawlerRunner
class MySpider(scrapy.Spider):
# Your first spider definition
runner = CrawlerRunner()
runner.crawl(MySpider)
deferred = runner.join()
deferred.addBoth(lambda _: reactor.stop())
reactor.run() # the script will block here until all crawling jobs are finished
The
deferredobject is the return value ofjoin()method when all the crawlers have completed their execution.After that, you should shutdown your reactor, that’s why you must add a callback method to
addBoth()deferred’s method wich callsreactor.stop()to stop the reactor.
Conclusion
Scrapy is a powerful and complete package for downloading web pages, processing them and save it in files and databases, but there are some other librairies that are doing a pretty job for scraping and deserving to be learned as well. Some of the disadvantages of Scrapy is that it requires more time to learn and understand how it works, but once learned, the process of making web crawlers will be easy. I hope you like my blog despite I didn’t explain all the boundaries of Scrapy but I talked about the relevant points. Enjoy it 😃😃 !!